
Almost any 21st-century project requires flexibility and scalability from an architectural point of view. Especially when it comes to chatbot development – if the customer wants to broaden functionality, carry some fresh ideas in, and suggest user new handy features. Push notifications are not a brand new feature, but it’s something that can be developed in an architecturally rational way. In this article, we’ll show you how.

By the way, in an era of extremely popular technology development, it’s virtually impossible to keep up and choose the most current tools. But is either the developer or the project owner, you should clearly understand that choosing the profound “starter pack” from the very beginning is the key to success.
So, hope this, as one of my best practices, is worth reading at least for comparison reasons (and certainly, this is not a very single solution).
The Problem
Imagine that your retail chatbot sells sports gear, providing lots of customers with a pretty nice service: answering all the typical questions, accepting, processing orders, and in general a lot of manual work has been automated. But you feel like the bot is somewhat raw and missing auto-mailing and the system for long-term processes. Your employees are still writing out the messages about each product delivery manually, and customers have started to subscribe to another service that provides them with something more than just online-purchases: reminders, news, interesting updates, discount notifications, and the wished product availability.
Don’t you miss the push notification service in your project?
Tools to tackle it
No doubt that a student can set a cron-scheduler at the server that will execute an action at a specific time on a recurring basis – very quick, but a primitive solution for such a worthy project. Amongst the main problems:
- Cron is a system-level process, run on RAM. It’s not even about the limits you may face, but more about the accuracy. Moreover, what about clean up after the server reboot or an unhandled failure?
- Being not an application process, Cron tangles the development process. Cron may even run at a different time than expected after the server timezone is changed – something that developers shouldn’t worry about, but would.
- Smallest resolution – 1 minute – you can’t schedule a task that needs to be executed every 30 seconds
- No queueing – you cannot specify an order for the jobs to complete, to divide them logically and finally make sure that they work independently
- Dynamic params – imagine you are eager to send some specific text to all users this evening, in 5 hours. If you use the Cron you should create a new CronJob, hardcode the text, build and deploy – sense the difference?
You may investigate more on the weak sides of the Cron scheduler here and there, to be aware of the issue, and keep pace on issue updates.
Bull – is one of the most rational solutions right now, having integrated which allows you to solve the above-highlighted problems and be powerful in scheduling and managing tasks.
Here is a list of the tools that I prefer using for one of the potential architecture solutions. Also, I won’t dive into AWS services launch configuration details, or Redis setup possible problems, but you will definitely understand the general idea and the short hands-on during the article. In this “recipe” you’ll need:
- Node.js server
- Bull + Redis
- AWS EC2 + start scripts
- AWS Auto Scaling Group and AWS Elastic Load Balancer
Into the stack
1. Node.js server
You may use anything for building your API that will be responsible for managing queues. From Express.js to hapi – anything you do prefer. The routing system /queue/:name should include:
HTTP method |
route |
description |
| POST | – /job/:type | define the delayed job or create & start the repeatable job |
| GET | – /jobs
– /jobs/:id |
get the list of all (one) jobs, may pass statistics, count, etc params |
| PUT | – /pause
– /resume – /empty |
manage any queue type in the general conception; empty means removing all jobs from the waiting list |
| PUT | – /retry/job/delayed/:id
– /promote/job/delayed/:id |
manage the queue with delayed jobs – promote (force start the job that is in the waiting list) or retry if any has failed |
| PATCH | – /job/repeatable
– /job/delayed/:id |
change data or opts fields to modify or reschedule the job |
| DELETE | – /job/repeatable
– /job/delayed/:id |
remove either single delayed job by id, or all repeatable jobs from the queue (as all have common time settings) |
where :type – the queue type (repeatable/delayed). It’s important to highlight that there are different Bull queues and job methods for the edit and delete processes for different jobs type – so it’s important to diversify them through routes. For instance, to update the delayed job – you should fetch the target job through queue.getJob , and then use job.update(newData), while for repeated one there will be the next action order queue.removeRepeatableByKey -> queue.add.
By the way, a nice solution will be to write the Bull wrapper. QueuesHandler – is the “list” of imported queues handlers from folders /queues/delayed and queues/repeatable. If you’re keen on Typescript – the piece of code below will be even much nicer:
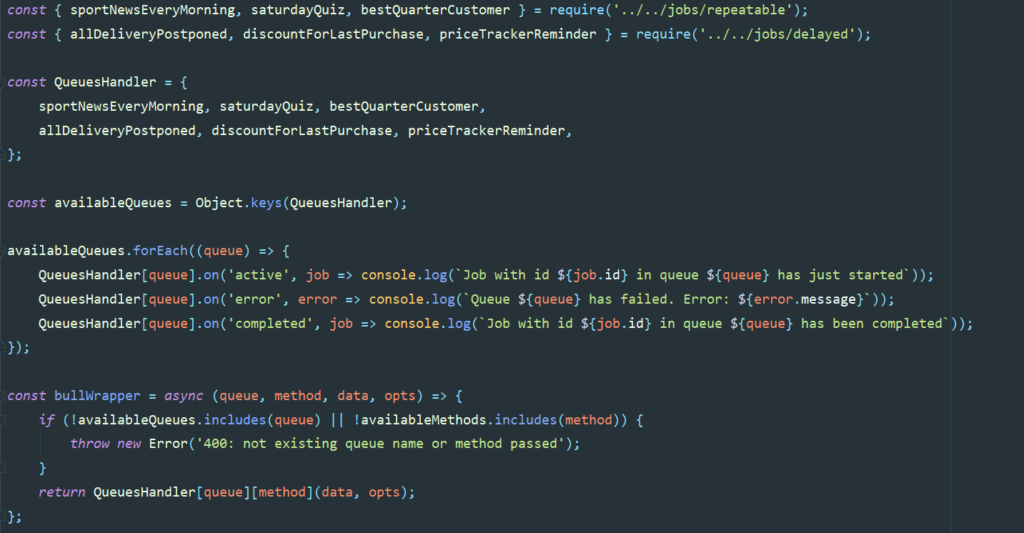
Bull offers a great list of queue events, so you may be sure that you will miss nothing. Detailed info about:
2. Bull
Bull is a Redis-based queue service for Node.js (if you still are not familiar with the basics of Node.js – we strongly recommend you pass the Node.js tutorial first).
Previously, there was the light alternative – Kue, but now it’s no longer maintained. Anyway, Bull has a list of privileges such as repeatable jobs, atomic ops, and rate limiters. Moreover, there is even the Web GUI working for Bull queues called Bull Arena.
The advantages of the Bull:
- Low CPU use and high performance. For the cases of huge mailing, the AWS ASG will automatically take care of this.
- Allows to execute asynchronous functions
- No limits for queues creation – just divide and conquer. Create as many queues with custom time rules for each and manage them easily.
- Update, remove, promote, pause and resume – play the queue around however it’s needed
- Jobs history – you may review all added, executed and even failed jobs with the saved error message. The statistics method allows seeing the queue summary
- Error handling – there are events, that may catch the error, failure, and the cases when the queue was stalled, drained. Define the convenient handler for these cases and be sure that your developers receive the mail and you get the nice message from your Admin bot telling that planned New Year congratulation for your customers wasn’t finished so that your team will quickly check the stuff.
Disadvantages
- no service is 100-percent perfect. The project is maintained and always-improved. You may find out more about their current bugs and their statuses on their GitHub page.
What is the queue? This is the imaginary bucket, in which we may gather jobs, each with its own time settings (in 5 minutes, tomorrow at 10 AM, every Sunday), and for all jobs in this bucket, there will be a predefined process handler (function to execute). The handler is called when the time “comes” – either for all jobs in the queue (repeatable) or for a single one from the queue of the delayed ones. We really recommend you separate queues for each repeatable job and for the delayed purposes, even if they have the same executor, but different appointment:

You may associate the queue with buckets with clothes to-wash that’s of different colors, texture and different powder intended to be used; or as if it’s your daily tasks sorted in work/study/sport/food/ sleep blocks, whatever you like. The main idea is: virtual alarm (Redis) says oh, it’s right X timestamp now (execution time is configured in job opts), you have definitely something scheduled in Y queue, please check – then you just quickly “remember” (bull process on listener) the action (function) and execute it. It doesn’t work every second or millisecond – the alarm knows the exact time points and reacts only if the current time is equal to one of them.
Time settings: this virtually divides the Bull jobs into 2 types: delayed and repeated. Delayed job – this is a scheduled job executed once at this specific time in the future. For instance, “We have just sent your order in the Postal office. Here is your invoice number and please wait for the next notification that will count your buyer score.” The Bull’s add event literally stands for creating a job in the queue with delay field in the opts object and making the job in this queue “wait” for it’s appointed time (will see the difference with scheduled).
Value\Queue type |
Delayed-jobs queue |
Repeatable-jobs queue |
Data |
different | common |
Time settings |
different | common |
Handler |
common | common |
Executed |
once | endlessly (until terminated) |
Repeated job – a job, that is configured with endless execution every X days/hours/minutes, whatever. To contrast the delayed jobs – bull’s add event, in this case, means creating this event once, and I will work endlessly every XXX milliseconds (under the hood) until the queue is not emptied (by your request or thanks to another scheduler). For example, a sports news daily digest, every 3rd Friday feedback gathering or even every 1st January special 50% discount promotion code for regular customers. You may pass one of the next options in the opts.repeat field when adding the job:

3. Redis
Redis – in-memory, run on RAM key-value storage used for reducing the load of the databases and increasing app performance, the prevailing concurrent of the Memcached and the leader on the caching ring for now.
Here is a great tutorial about manual Redis setup a Linux Machine – you should choose the Amazon Linux 2 AMI for your EC2.
The Redis plays a background role in this service, we just need to prepare it for the Bull, but we do not actually use it directly. In simple words, under the hood Redis helps to save 2 values: time and queue name. Then the Queue.process(job => /*job.data manipulation*/) handler takes everything into his own hands:

4. AWS EC2 machine
It’s not a secret that AWS EC2 is the most popular AWS offering. Go to the EC2 Dashboard, choose the closest region and launch the instance. Configure the instance whatever it’s needed, but pay special attention to the Security Groups’ configuration – they control inbound and outbound traffic. In the Configure Instance tab you’ll see the advanced details chapter – here you should find the User Data input field. Prepare your build & start scripts and paste them right there.
The #!/bin/bash script should be responsible for:
- Installing updates
- Installing the software (node.js in our case)
- Cloning (downloading) the project
- Installing dependencies
- Starting the server
Furthermore, consider the safe storage for your .env file – there may be important credentials for accessing your database and the API keys. We highly recommend you to think about AWS KMS encryption beforehand, as well as paying attention to the AWS Secret Manager.
For the CDE reasons (continuous delivery) it will be perfect to configure AWS CodePipeline at your cloud virtual machine, that will automatize build and deploy stages, but this article doesn’t cover this point in detail.
5. AWS Auto Scaling Group
AWS Auto Scaling Group – this service will help us to scale out or scale in automatically, depending on the load. Regarding the fact, that we have supposed that your retail bot has or plans to have a billion customers – this service will definitely make a positive impact on our notifications service.
For instance, if the load increased on any even custom metric rule – the ASG would automatically register the new instances and start the instance based on the script (use the one you created on step 4). There may be average CPU usage defined as the Auto Scaling Rule (for example, CPU should be <= 40%), and the CloudWatch alarm will monitor it. For the custom metric case – reference AWS PutMetricData API and create the CloudWatch metric manually.
You should define the maximum (min = 1) instances running, and ASG will never exceed this limit. Another great advantage of the ASG is that it will automatically restart the instance if it gets terminated and will replace the unhealthy instances (will highlight the health check in the paragraph below).
In fact, Auto Scaling Groups are free, you will be billed only for the launched instances.
6. AWS Elastic Load Balancer
AWS Elastic Load Balancer – the name speaks for itself: the service will spread the load across multiple downstream instances. Moreover, it will expose a single DNS and redirect the traffic in case of failures – the fantastic power of AWS!
What is important to know: there is a handy possibility to configure the health check for the instances: which route should be called, what response should we expect, how many times we should try to be sure it’s a success and how many times it’s enough to get it as the failure. Add this one for your app to let the AWS manage the unhealthy instances on its own.
Moreover, knowing the Security Group features well – you may easily make the inbound traffic come only from the Load Balancer to your app, so no one will make the use of EC2 IP(s).
Conclusion
I hope the article was interesting for you, and you learned something new. Feel free to write comments, ask questions and liven the discussions up – we’ll be grateful to receive your feedback. And the architecture diagram should serve as a good summary of the article:

Also check out an article How To Build A Scalable Chatbot Architecture From Scratch
 Five Chatbot Use Cases for Apparel Industry
Five Chatbot Use Cases for Apparel Industry How to Create a Telegram Reminder Bot Using Node-RED
How to Create a Telegram Reminder Bot Using Node-RED How to make a Reddit bot with Python
How to make a Reddit bot with Python Node-RED vs Cognigy - what is your digital choice?
Node-RED vs Cognigy - what is your digital choice?